Table of Contents
- Introduction
- Enterprise Access Model
- BloodHound and Detection
- BloodHound Enterprise
- Entity Based Detection Engineering
- Kerberoastable Users
- Principals with DCSync Rights
- BloodHound Enterprise as a Detection Control
- Conclusion
Introduction
Detection engineers often have a difficult time determining:
– What do we detect?
– Where do we detect?
– Who do we detect?
One approach is to look at the organization’s entities and evaluate the criticality of those entities. In detection engineering, we define high-value entities as classified intellectual property or critical portions of production infrastructure. With this definition in mind, detection engineers can focus on the high-risk or high-value objects within an environment to narrow the focus of detection to a specific scope of unique objects within the environment.
Entity-based detection engineering focuses on the high-risk or high-value entities that may provide a high reward for an adversary. Because these high-value targets can be critical systems for operation or contain intellectual property, detection engineers can layer additional monitoring within the scope of these assets to help with alert prioritization and elevate detection visibility of high-risk targets in the environment.
This can be a monstrous task for larger production environments and detection engineers can get lost determining the prioritization of which objects to add additional auditing. To narrow the focus of alerting to unique objects within the environment, we will look at an Enterprise Access Model, Using Bloodhound and Bloodhound Enterprise for Detection, and the Entity Based Detection Engineering Methodology.
Enterprise Access Model
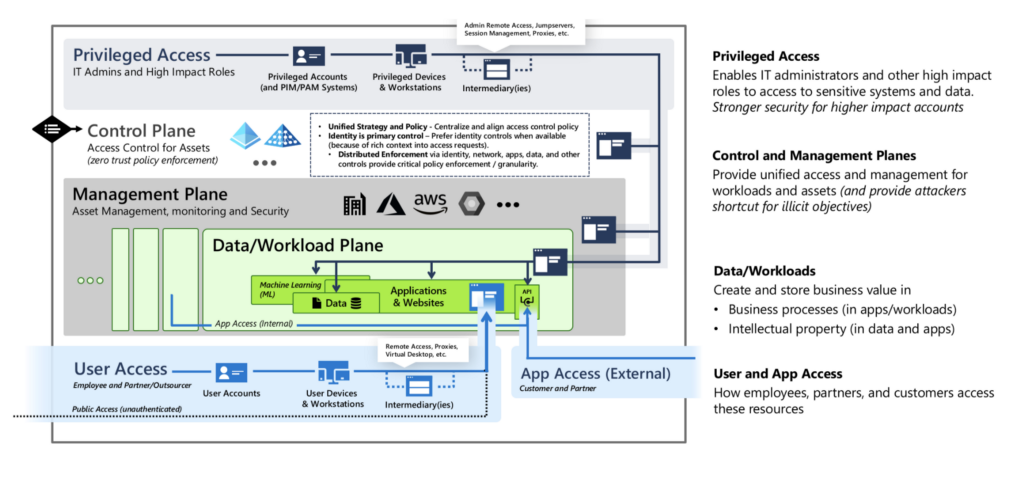
Microsoft’s Enterprise Access Model defines Tier 0 as the element of an enterprise containing high-impact roles, sensitive systems, critical data, and requiring privileged access. The principals within the Active Directory environment that can modify or have direct access to Tier 0 are considered Tier 0 principals. An adversary's journey from Tier 2 or Tier 1 to gain access to Tier 0 is considered the attack path. Defensive teams have adapted the process of discovering attack paths that involve Tier 0. Detection engineers utilize this process for the prioritization of auditing. Utilizing this methodology has been a very labor-intensive process. Bloodhound Enterprise automates this labor-intensive process by discovering and prioritizing attack paths that adversaries could use to achieve Tier 0 access.
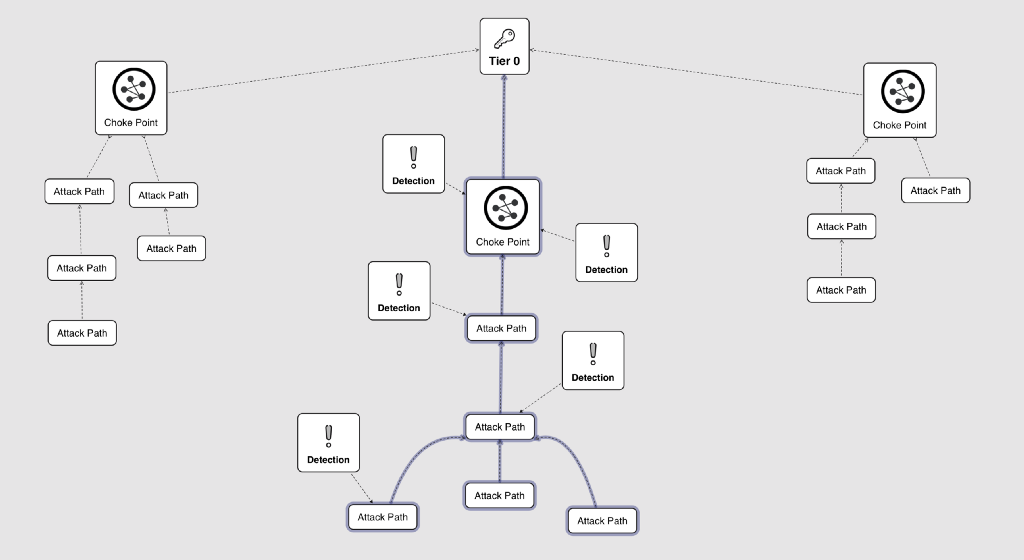
Many organizations will separate their environments into three Tiers for simplicity.
- Tier 0: Domain Controllers, Security Groups, Domain/Enterprise Administrators, and Business-Critical Assets
* Can directly influence any object within the Windows Active Directory Environment
* Administrators at this tier can modify Tier 0, Tier 1, and Tier 2
** Administrators at this tier should only interactively log on to Tier 0 - Tier 1: Application Servers, Cloud Services
* Can influence objects within these endpoint types, with moderate impact on business continuity
* Administrators at this tier can modify Tier 1 and Tier 2
** Administrators at this tier should only interactively log onto Tier 1 - Tier 2: Workstations
* Can influence objects within workstation asset types, with minimal impact on business continuity
* Administrators at this tier can modify only Tier 2
** Administrators at this tier should only interactively log onto Tier 2
BloodHound and Detection
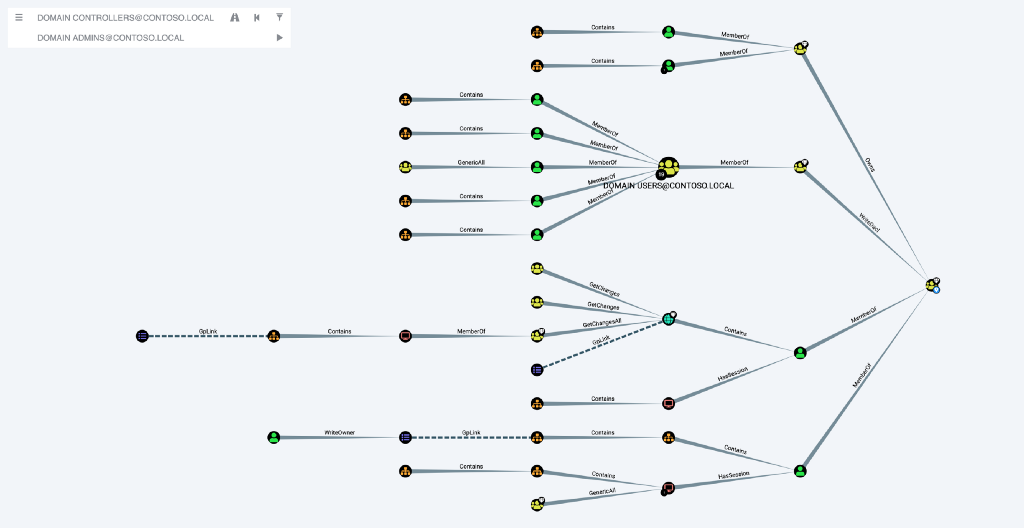
BloodHound is a graph theory reconnaissance tool that adversary simulation teams have used for a little over half a decade now. The tool utilizes the NetSessionEnum Windows API function to provide the adversary simulation team detailed information on sessions established locally and remotely throughout the Windows environment. BloodHound also gathers the Group Membership, Access Control Lists, Object Properties, Trusts, Containers, and Group Policy Object Administrators from the Domain Controller’s Active Directory User and Computers Database. With this combined information, relationships are derived and attack paths are generated.
Note: BloodHound is free and open-source software. You can audit all the code for BloodHound and SharpHound here.
Defenders utilize this methodology to determine the attack paths within their environment. Detection engineers can audit for specific interactions with Tier 0 assets by determining which attack paths are available within the layout of the AD structure. However, Tier 0 principals can exceed the capability of programmatic auditing which can cause a substantial increase in response time. In multi-domain organizations, there can be thousands of endpoints with even more Active Directory principals, each with its own unique attack path to Tier 0. This leaves defenders with the problem, “Which of these attack paths will benefit most from additional auditing?”
BloodHound Enterprise
BloodHound Enterprise builds upon our knowledge of Active Directory and the attack paths that we have seen abused. Our product highlights the critical chokepoints that an adversary must traverse to propagate to Tier 0, thus enabling security engineers to develop a conceptual bastion. BloodHound Enterprise calculates the criticality of attack paths utilizing Microsoft’s Enterprise Access Model and determines the priority of bridges that the adversary must pass.
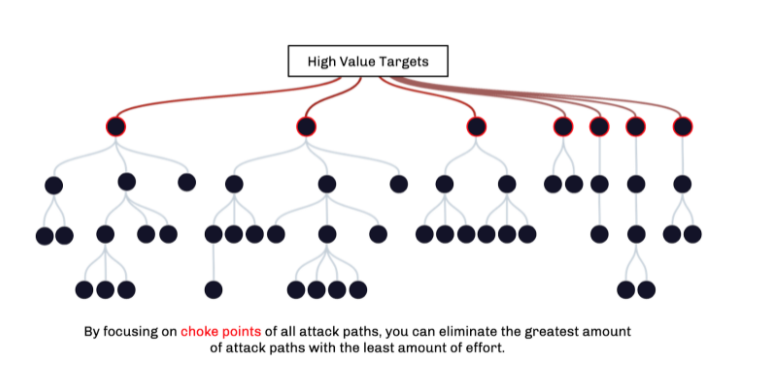
Adversary simulation teams enumerate attack vectors and provide details into which path was utilized, but both defenders and security engineers are responsible for interpreting those details in a way that eliminates that specific attack path. Defenders are then faced with the problem, “Which part of the kill chain needs to be remediated?” Oftentimes, security engineers remediate low-value pivot points in an attack path but do not realize that the most high-value junction in the attacker’s journey lies further on down the line.
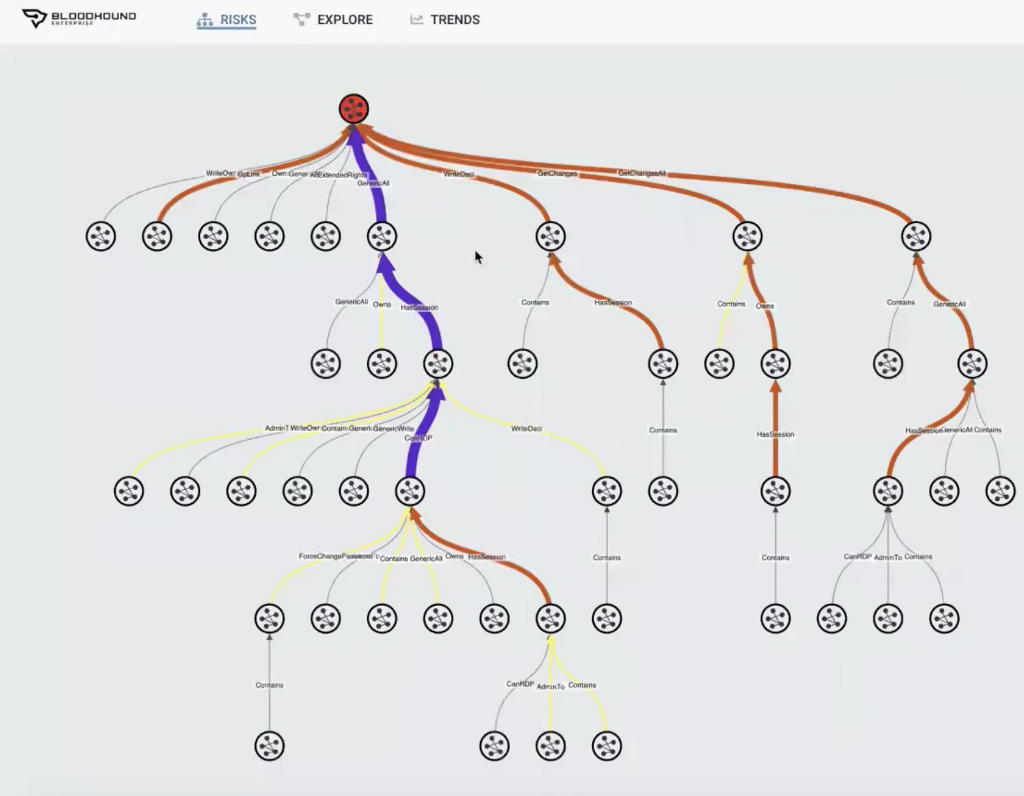
BloodHound Enterprise enables security engineers to know the exact chokepoints around accessing Tier 0, thus allowing engineers to fortify these critical pathways in their environment. BloodHound Enterprise also accounts for Tier 0 users that utilize the Tier 0 principles appropriately. For example, a security engineer utilizing Tier 0 access to modify GPOs or create new user accounts is expected behavior and not flagged as malicious for the purpose of accessing Tier 0. If a principal with Tier 0 access logs into a workstation interactively and caches their credentials into the Tier 2 workstation; this attack path is identified and empirically scored for criticality against the other attack paths identified within the environment.
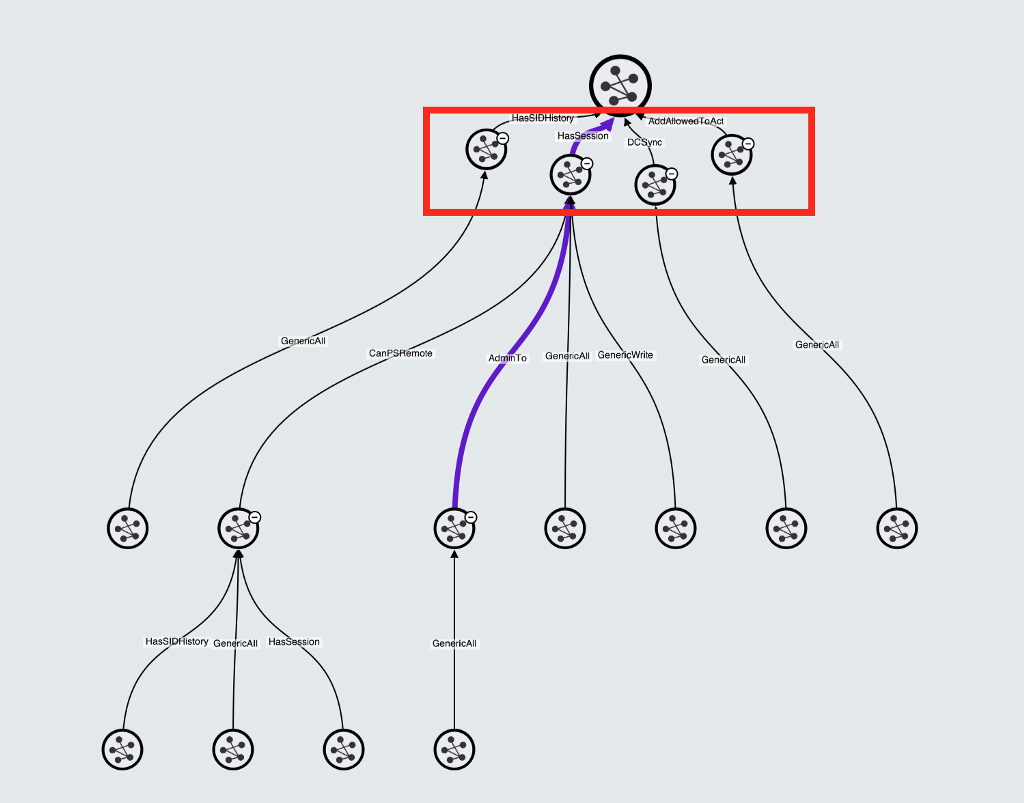
Each attack path enumerated by BloodHound Enterprise includes practical remediation strategies specific to your environment. Security engineers utilize BloodHound Enterprise to monitor attack paths, reconfigure their environment, and enhance their organizations' security posture. Detection engineers can complement the security engineers’ effort by utilizing this data to enhance the fidelity of alerts aligned to the identified critical attack paths.
Entity Based Detection Engineering
From a Detection Engineer’s perspective, the prioritization of attack paths for a client environment is incredibly useful for determining which exact entities to audit explicitly. Knowing the criticality of these attack paths enables detection engineers to hone in the scope of their efforts, allowing them to create meaningful detection strategies around the most dangerous attack paths. While BloodHound Enterprise aims to eliminate attack paths from the environment, we as detection engineers can supplement the most critical chokepoints in the environment with auditing and defensive controls until those attack paths have been minimized or eliminated.
BloodHound Enterprise empirically scores the attack paths enumerated by the number of entities with access to Tier 0 found within the specific attack path. A priority of creating detections can be started by focusing detection engineers on the critical attack paths that utilize credential access techniques involving Tier 0 principals. For example:
- Kerberoastable users
- Principals with DCSync rights
The method of abstracting target techniques and developing detections for the attack techniques found within the attack paths can output to the overall Monitoring function. The emphasis of criticality should be focused specifically on the accounts, groups, and Tier 0 principals found within BloodHound Enterprise attack paths.
Kerberoastable Users
Kerberoastable accounts create a scenario that makes use of service accounts and their pre-configured permissions in their environments. The default authentication model within Kerberos provides an attack vector of brute-forcing the service account’s password offline when a principal requests a Ticket Granting Service (TGS) during a service request.
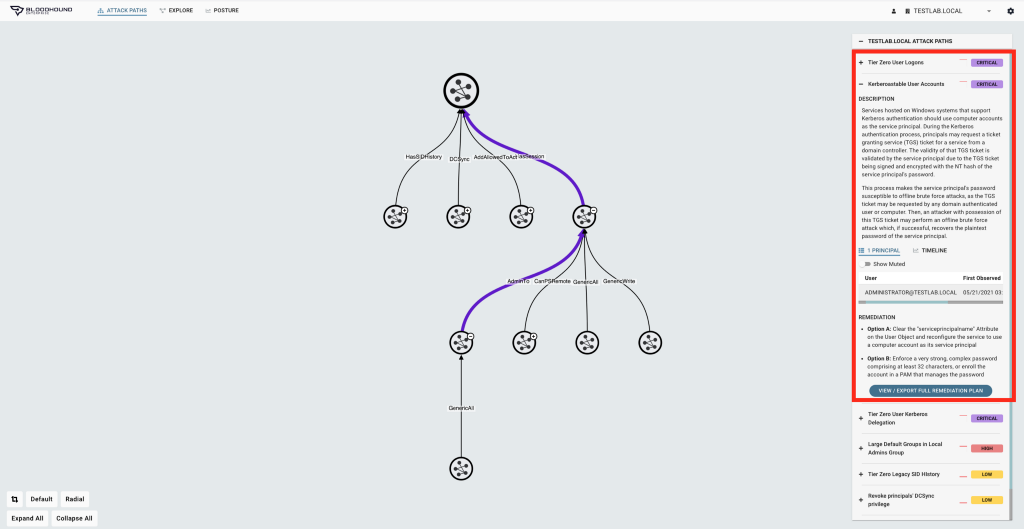
Kerberoasting traverses a couple of different common denominators that can act as a nice compromise between precise and broad detections. We can abstract the execution of Kerberoasting into a few different methods that can make use of the same chain of events:
- Service Account is enumerated
- Service Ticket is requested
- Service Ticket is cracked offline
- Service Account authenticates via a cracked service ticket
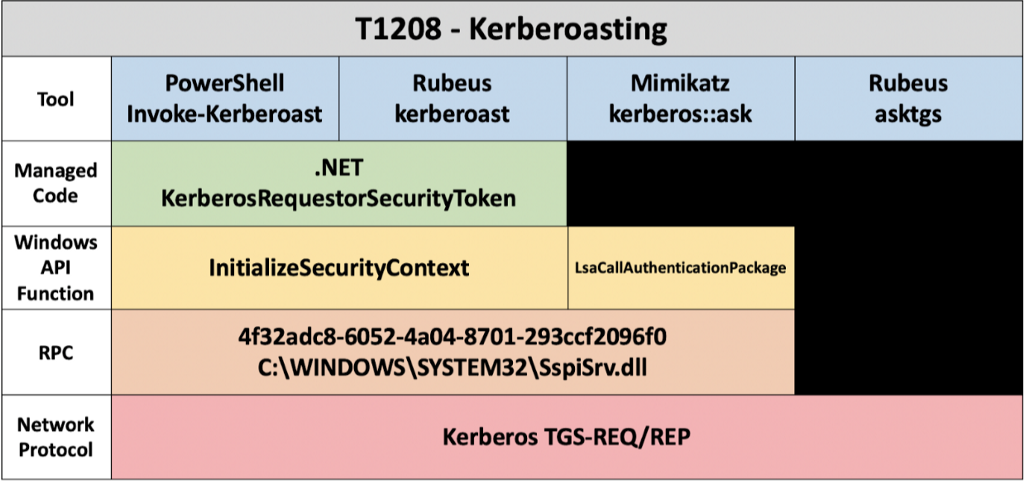
The above is an example of the abstraction map that aligns to MITRE Steal or Forge Kerberos Tickets: Kerberoasting — T1558.003. The beginning of the map provides four examples of attack proofs-of-concept that enable us to validate the underlying technology used with Kerberoasting. Utilizing the Detection Engineering Methodology, we have mapped the common denominators between multiple implementations of this technique execution.
Historically, detections written to identify Kerberoasting are aimed at a multi-layered approach (ex. Detection in Depth). This detection strategy audits multiple events to create an overall composite event monitoring the different portions of the technique execution.
The actual number of service requests that the analysts can classify as benign or malicious will operate within the threshold of the security operating center. In the event, that the Kerberoastable service accounts cannot immediately be remediated, as is sometimes the case, monitoring for anomalous source host ticket requests and anomalous successful logins from service accounts enables the monitoring team to cover down on the blind spots that the previous layer of detections will miss.
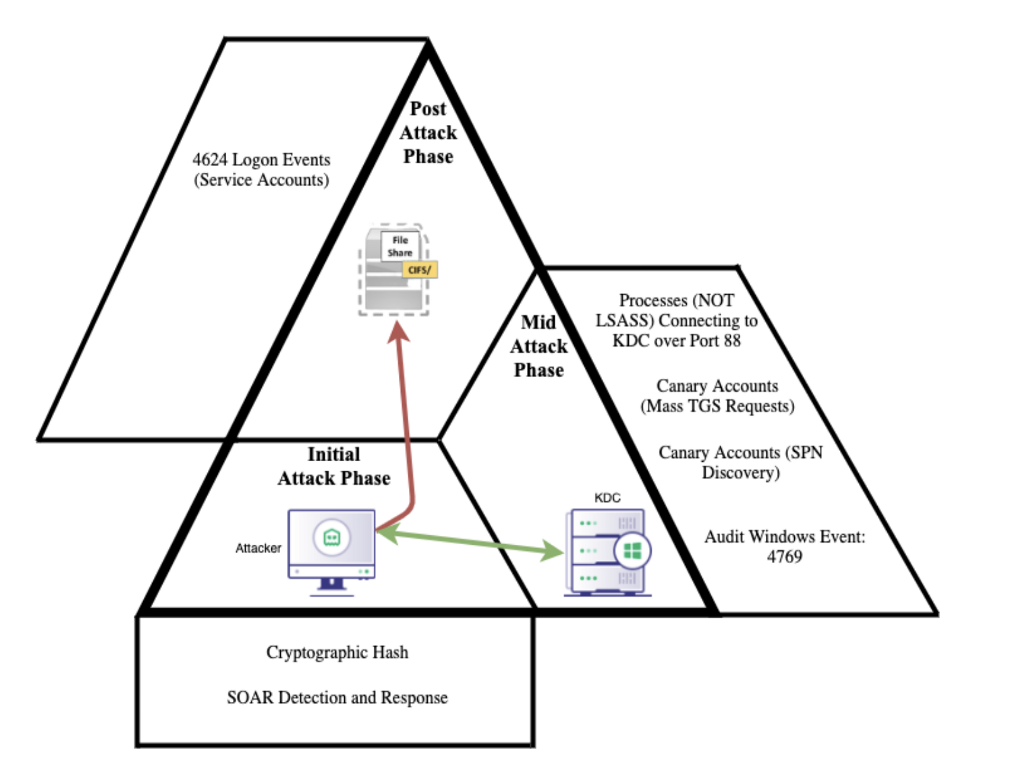
The above represents a layered detection strategy that covers the blind spots that each previous detection strategy will inherently have. Some of the detection types within this mapping are more precise than others, but that works to the defenders’ advantage. We can begin to derive the technique execution from multiple perceptions of the telemetry by layering our detection strategies.
Combining the anomalous Service Ticket Requests with unique successful logins of service accounts enable a layered strategy that identifies multiple implementations of the attack technique. Utilizing the Kerberoastable service account attack path from BloodHound Enterprise as a point of pivoting, detection engineers can audit the Tier 0 principals found within the attack path. Auditing Sysmon Event ID 1 (Process Creation) and Sysmon Event ID 3 (Process Established a Network Connection), detection engineers can correlate these events with the Domain Controller’s Windows Security Event ID 4769 (Kerberos Service Ticket was Requested). This strategy will identify an LSASS spoofing process attempting to request a service ticket.

Alternatively, detection engineers can audit the post-attack phase with Windows Security Event ID 4769 (Kerberos Service Ticket was Requested) and Windows Security Event ID 4624 (Successful Logon), within a short temporal proximity. This strategy identifies the anomalous authentication of the cracked service accounts to unique hosts within the organization.

Principals with DCSync Rights
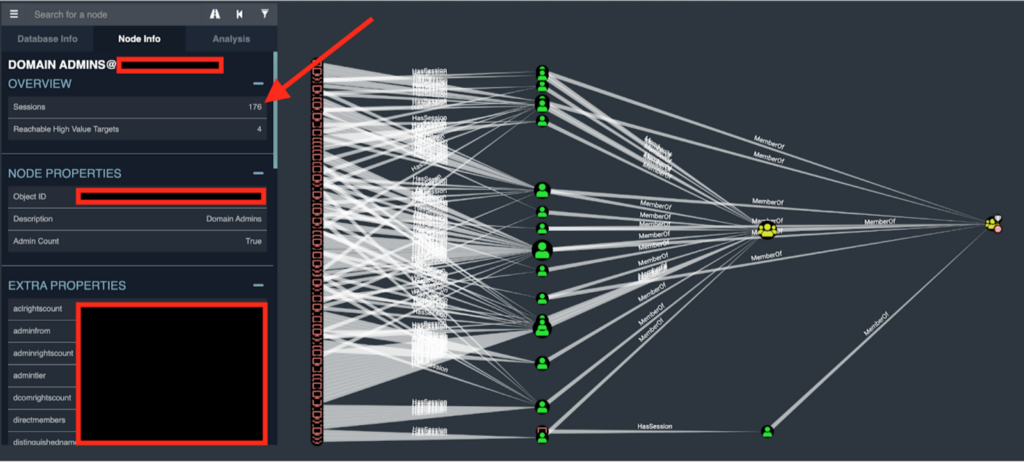
DS Replication occurs natively between domain trusts and clustered domain controllers. The criticality of a Tier 0 user having access to these permissions cannot be underestimated. The DS-Replication permissions (whether through direct or group membership permissions) enable the user to request the credential material (specifically the NT hash) for any user, including the KRBTGT service account. Many organizations provide the necessary privileges for DCSync (DS-GetChanges, DS-GetChanges-All) to Tier 0 users. When an adversary obtains the NT hash for the KRBTGT account, an adversary may provide themselves access to any remote resource that authenticates to that specific Domain Controller’s KRBTGT account. This sequential technique is called a Golden Ticket attack because the adversary uses the NT hash of the KRBTGT account to authenticate themselves and obtain the KRBTGT Kerberos Authentication token.
As advised in Andy Robbins’ blog, “Bloodhound versus Ransomware — A Defender’s Guide,” auditing for highly sensitive principals and their privileged behavior can enable detection engineers to key in on activity that may indicate an attacker-controlled privileged account. The DCSync target technique generates quite a bit of detection opportunities that detection engineers can use in their development of a minefield around the attack path prioritized by BloodHound Enterprise. As skillfully described in Jonathan Johnson’s SO-CON 2020 presentation, DCSync utilizes the Directory Service Replication Service RPC protocol which generates both host and network traffic.

The above is an example of the abstraction map that is aligned with MITRE OS Credential Dumping: DCSync — T1003.006. Starting with the beginning, Jonny identified multiple implementations of the technique execution with some very well-known attack tool proofs-of-concept. As the map indicates, specific extended rights are utilized in the execution of this technique. It is important to understand that these extended rights can be granted to more than just Tier 0 users, and security group permissions should be considered as well. Also, note the network protocol layer that Jonny’s research identified as well. This will enable us to create a detection that many detection engineers overlook.
Detection Engineers can focus their auditing on the privileged users highlighted by BloodHound Enterprise and determine process execution where Sysmon Event ID 1 and Windows Security Event ID 4662 (An operation was performed on an object) occur with the Object Class identified in the 4662 event is Domain-DNS Class(object) — Schema GUID: 19195a5b-6da0–11d0-afd3–00c04fd930c9 and the Extended Rights are DS-Replication-Get-Changes-All — Schema GUID: 1131f6ad-9c07–11d1-f79f-00c04fc2dcd2.

One of the unique forms of telemetry that Jonathan Johnson discovered while researching DCSync is the network connection between the compromised host request to the DS-Replication Service. This activity can be identified over the wire via the DRSUAPI network protocol. Detection engineers can audit the Tier 0 principals identified with BloodHound Enterprise and highlight with user behavior matches that of DCSync. Host-based telemetry will indicate the network connection to the Domain Controller was established with Sysmon Event ID 3 and Event ID 5156 (The Windows Filtering Platform has permitted a connection). Telemetry such as Zeek can validate the connection utilizing the DRSUAPI network protocol.

BloodHound Enterprise as a Detection Control
In some situations, investigation and response is a more appropriate exercise than laying down detections for a particular attack path. In the scenario of Tier 0 users logging in interactively, BloodHound Enterprise will act as the Detection Control and the Monitoring function can utilize this highlighted attack path to pivot the investigation to a narrow scope of the Tier 0 users. Additionally, BloodHound Enterprise can be utilized to empirically prioritize the alerts that are already in production. Moving from the Detection Phase to the Triage phase of Jared Atkinson’s Funnel of Fidelity, enriching our alerts with relevant forms of context can enable the Monitoring function to properly prioritize the alerts that are being presented to them.
Conclusion
Detection engineers have opportunities to focus the alerting based on the criticality of our entities. We explored methodologies that allow us to prioritize and build robust detections in our environment which can increase the fidelity of our alerts. We identified a potential solution that will help in the prioritization and monitoring of our high-value entities using BloodHound Enterprise and can even leverage the tool as a way of continuous monitoring for these gaps as a detection control. These strategies and BloodHound Enterprise can be used to help point the monitoring function in a critical direction with the ultimate goal to improve visibility and the overall security posture of your organization.
Entity Based Detection Engineering with BloodHound Enterprise was originally published in Posts By SpecterOps Team Members on Medium, where people are continuing the conversation by highlighting and responding to this story.